Mehrebenenanalyse mit R (HLM mit R)
– Visualisierung zum Explorieren der Daten
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 13.12.2023
Zu Beginn einer Mehrebenenanalyse ist es meistens hilfreich, wenn man sich die Daten zunächst einmal mit Streudiagrammen pro Level 2 Einheit ansieht. Dies macht es insbesondere leichter, später zu entscheiden, für welche Prädiktoren Random Slopes sinnvoll sind.
Dieses Tutorial zeigt, wie man mit dem Package ggplot2 entsprechende Scatterplots aufrufen kann.
library(ggplot2)
Für dieses Beispiel verwende ich den gleichen Datensatz wie für meine anderen Grundlagentutorials, aus dem Buch von Hox et al., Kapitel 2.
popular2neu <- popular2
Wenn man mit ggplot2 Streudiagramme getrennt je Level 2 Einheit aufrufen möchte, dann ist zunächst sicherzustellen, dass die Gruppenvariable (hier: class) als Faktorvariable angelegt ist.
popular2neu$class <- factor(popular2neu$class)
Wir werden für zwei Level 1 Prädiktoren Streudiagramme mit der abhängigen Variable (Popularität) betrachten, für die Extraversion der Schülerinnen und Schüler und für deren Geschlecht.
# Prädiktor 1: Extraversion
Es gibt im Prinzip zwei mögliche Darstellungsformen: Alle Slopes farbig in einer Grafik oder eine gesonderte (kleine) Grafik für jede Level 2 Einheit.
Die Grundeinstellung für ein Streudiagramm mit ggplot2 ist jeweils gleich:
Wichtig ist noch bei der Eingabe, dass das Pluszeichen jeweils am Ende der Zeile steht, damit das Programm weiß, dass der Befehl noch auf der nächsten Zeile weitergeht.
Hier kommt noch hinzu in der aes() Funktion die Angabe, welche Variable (Level 2 Einheiten) die Farbe steuert.
# 1a farbig nach Gruppe
ggplot(data=popular2neu,
aes(x=extrav, y=popular, color=class)) +
geom_smooth(method=lm, se = F, show.legend = F)
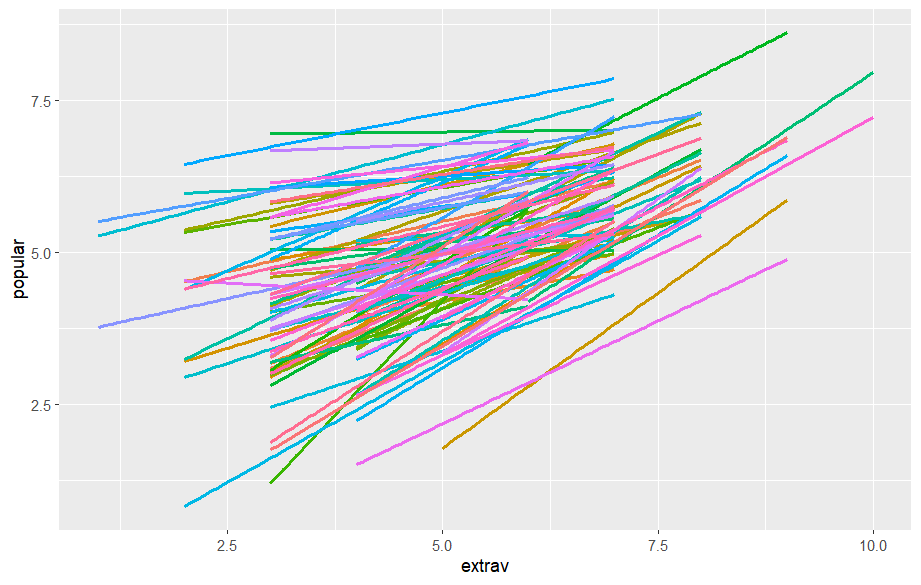
Wir sehen hier, dass es doch ziemliche Unterschiede im Zusammenhang zwischen Extraversion und Popularität zwischen den Level 2 Einheiten (hier: Schulklassen) gibt.
Bei einem gesonderten Streudiagramm pro Gruppe / Level 2 Einheit entfällt die Angabe der Farbe in der aes() Funktion. Stattdessen kommt hinzu facet_wrap(), wobei in der innersten Klammer der Name der Level 2 Einheit stehen muss.
# 1b gesondert je Gruppe
ggplot(data=popular2neu,
aes(x=extrav, y=popular)) +
geom_smooth(method=lm, se = F) +
facet_wrap(vars(class))

Auch hier sehen wir deutlich, dass es einige Gruppen mit sehr deutlichem Anstieg, andere Gruppen hingegen mit fast völlig flachem Verlauf gibt. Das ist ein starkes Indiz dafür, dass hier eine Random Slope sinnvoll sein kann, die ja Unterschiede im Anstieg der Regressionsgeraden zwischen den Level 2 Einheiten abbilden soll.
# Prädiktor 2: Geschlecht
# 2a farbig nach Gruppe
ggplot(data=popular2neu,
aes(x=sex, y=popular, color=class)) +
geom_smooth(method=lm, se = F, show.legend = F)
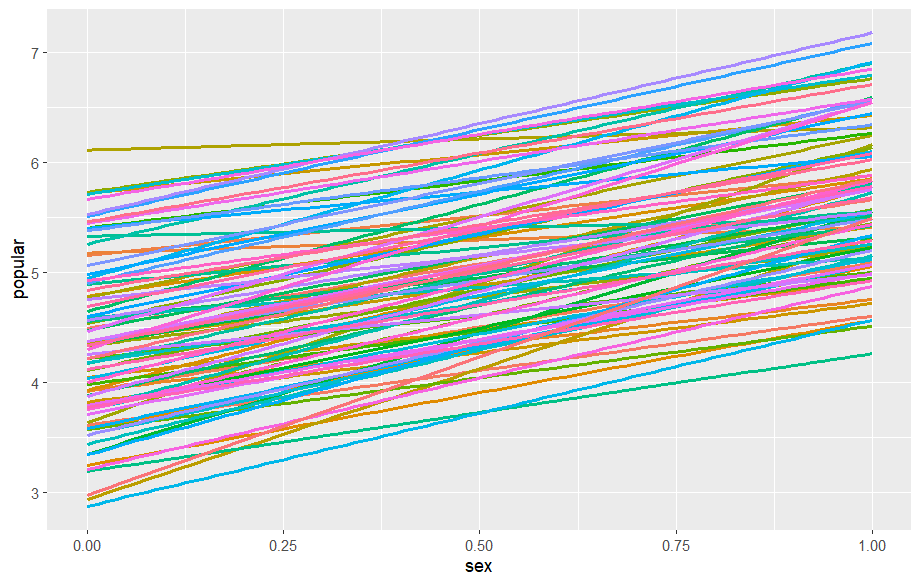
Hier sieht der Verlauf der Regressionsgeraden deutlich homogener aus (was es weniger wahrscheinlich macht, dass eine Random Slope vorliegt).
# 2b gesondert je Gruppe
ggplot(data=popular2neu,
aes(x=sex, y=popular)) +
geom_smooth(method=lm, se = F) +
facet_wrap(vars(class))

Auch in dieser Darstellung sieht man, dass im Vergleich zur Extraversion für das Geschlecht die Effekte relativ homogen sind. (Dass es für einige Klassen gar keine Gerade gibt, liegt daran, dass es dann Klassen nur mit Jungen oder nur mit Mädchen sind.)