Mehrebenenanalyse mit SPSS
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 17.02.2023
Dieses Tutorial zeigt Ihnen, wie Sie mit SPSS eine Mehrebenenanalyse durchführen können. Dieses Verfahren ist auch bekannt als hierarchisch lineares Modell (hierarchical linear modeling, HLM), als linear mixed effects model oder als random effects model.
INHALT
- Einführung
- Nullmodell
- Fixed Slopes / Random Intercept
- Random Slopes
- Cross-Level Interaktion
- Daten für Voraussetzungsprüfung
- Literatur
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
1. Einführung
Man verwendet Mehrebenenanalysen, wenn man sog. genestete Datenstrukturen vorliegen hat. Dafür gibt es zwei typische Beispielfälle.
Zum einen ist das bei gruppierten Untersuchungseinheiten/Versuchspersonen der Fall – z.B. Schülerinnen und Schüler genestet (= verschachtelt) in verschiedenen Schulklassen. Dieses Beispiel werden wir uns in diesem Tutorial ansehen. Als Level 1 bezeichnet man dabei die unterste Ebene, hier die Schülerinnen und Schüler. Und als Level 2 die höhere Ebene, hier die Ebene der Schulklassen.
Zum anderen liegt eine genestete Datenstruktur häufig bei Längsschnittdaten vor. Hier ist auf Level 1 die Ebene der Messzeitpunkte und auf Level 2 die Ebene der Versuchspersonen. Im wesentlichen läuft diese Analyse ähnlich wie bei einem genesteten Querschnittsmodell wie oben im Schulbeispiel. Jedoch sind dort einige Anpassungen erforderlich (insbesondere bei der Varianz-/Kovarianzstruktur), die den Rahmen dieses Tutorials sprengen würden.
Beispieldatensatz
Dieses Tutorial basiert auf einem Beispielsdatensatz von Hox (2010). Dieser ist unter http://joophox.net/mlbook2/MLbook.htm verfügbar. Die Auswertung folgt dabei Kapitel 2 aus dem Buch Hox (2010), dort finden Sie noch weitergehende konzeptionelle Informationen zur Schätzung des Mehrebenenmodells.
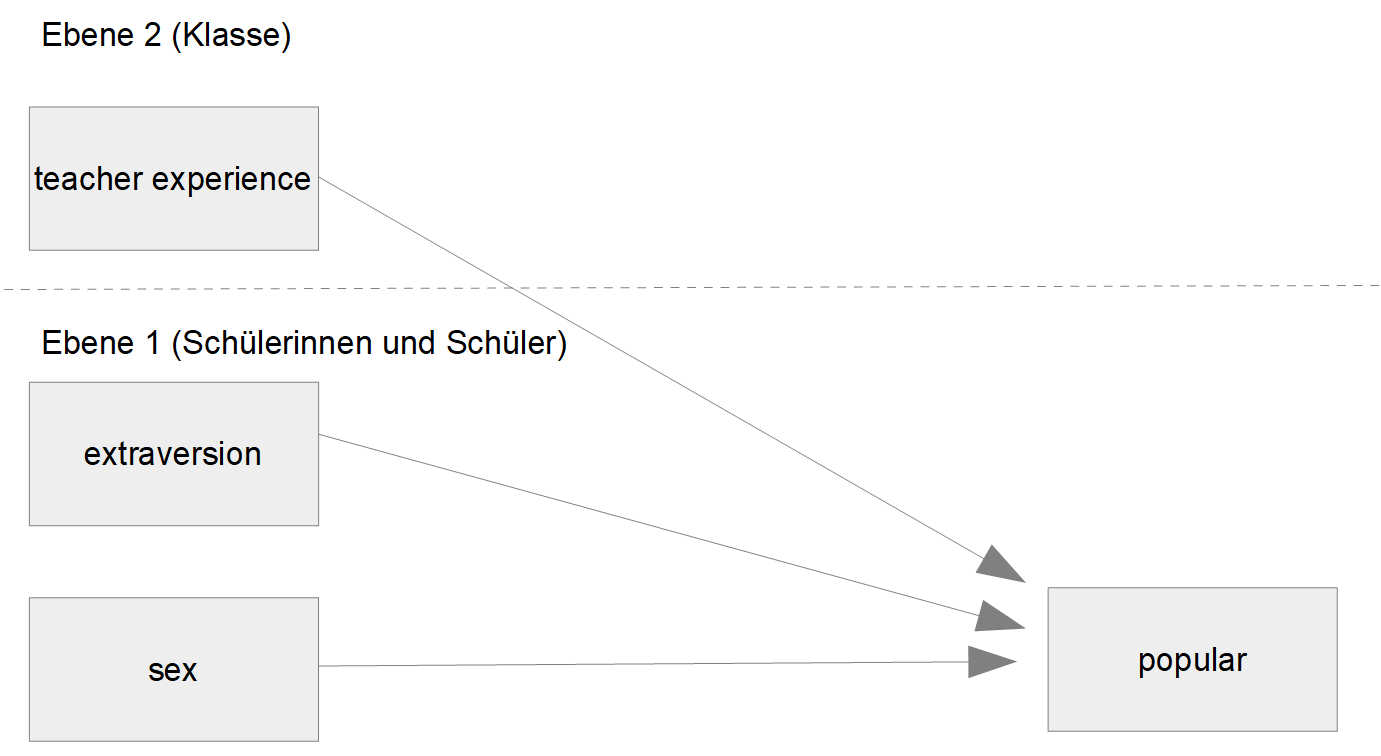
In diesem Datensatz haben wir Schülerinnen und Schüler, genestet in Schulklassen. Auf der Ebene der Schülerinnen und Schüler wurden u.a. erhoben deren Extraversion (extraversion) und deren Geschlecht (sex). Außerdem als vorherzusagende Kriteriumsvariable die Popularität der jeweiligen Schülerinnen und Schüler. Auf der Ebene der Klasse wurde die Berufserfahrung der Lehrkraft erhoben (teacher experience). Nun soll untersucht werden, wie diese drei Prädiktoren (Extraversion, Geschlecht, Berufserfahrung) zusammenwirken, um die Popularität der einzelnen Schülerinnen und Schüler zu erklären.
Entsprechend der Beispielauswertung in Hox (2010) wurde hier noch auf eine Zentrierung der Variablen verzichtet, auch wenn diese häufig zu besseren Interpretierbarkeit der Ergebnisse sinnvoll ist.
2. Nullmodell (leeres Modell)
Wir beginnen bei der Auswertung mit einem sog. Nullmodell (leerem Modell). Das ist im Grunde kein Modell, sondern es beschreibt nur die Variation auf den verschiedenen Ebenen. Mit dem Nullmodell kann man die Fragen beantworten:
Wie stark schwankt die Popularität zwischen den Schulklassen?
Wie stark schwankt die Popularität innerhalb der Schulklassen?
Aus diesen beiden Kennwerten kann man anschließend noch ein häufig verwendetes Maß für genestete Daten berechnen, die Intraklassenkorrelation (intraclass correlation, ICC).
In SPSS finden wir die Mehrebenenmodelle unter:
Analysieren – Gemischte Modelle – Linear
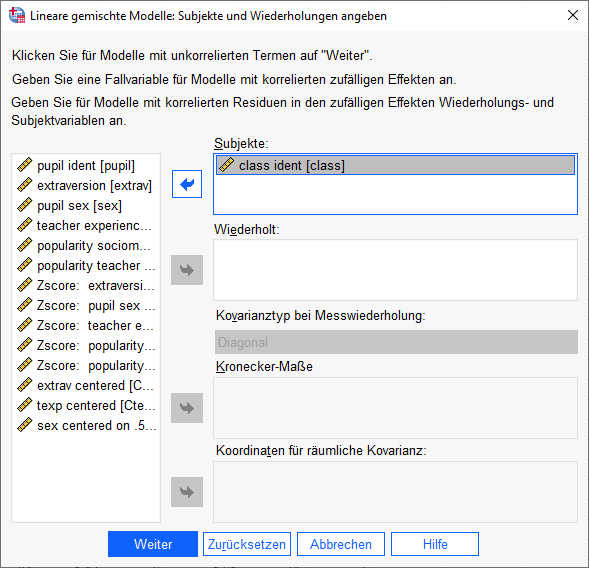
Im Einstiegsdialog ziehen wir die Variable, welche die Level 2 Einheiten beschreibt (hier: class), in das Feld Subjekte. Wichtig: Subjekte sind hier nicht die Versuchspersonen sondern die Schulklassen (die Versuchspersonen wären Subjekte in einem Längsschnittdesign.) Das Feld für „Wiederholt“ würden wir nur bei einem Längsschnittmodell benötigen.
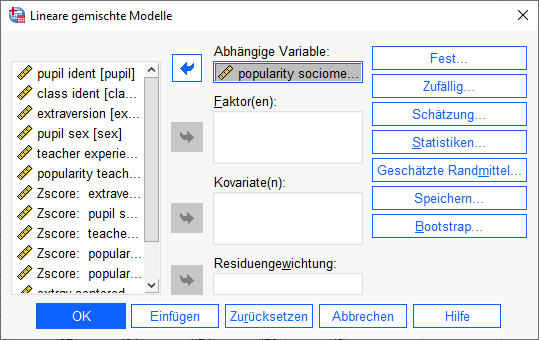
Beim Nullmodell haben wir noch keine Prädiktoren, so dass wir im anschließenden Dialog nur die Kriteriumsvariable in das Feld „Abhängige Variable“ ziehen. Anschließend müssen wir noch einige der rechts stehenden Schaltflächen für weitere Optionen bearbeiten.
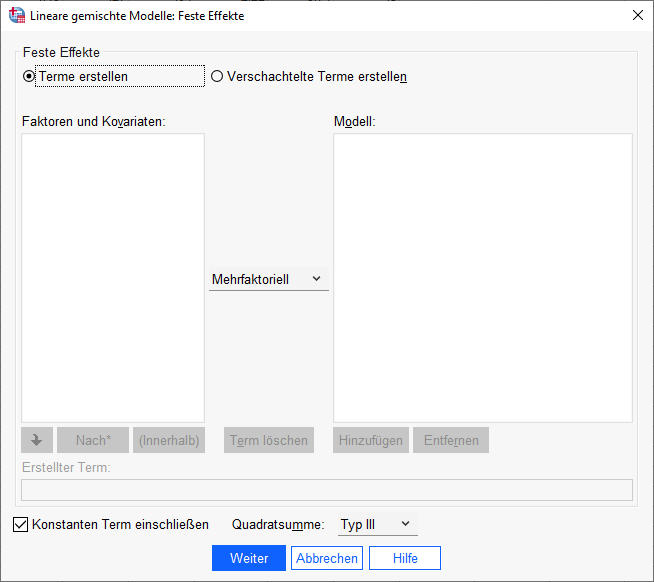
Bei festen Effekten (Menüpunkt: „Fest...“) müssen wir hier noch nichts einstellen, da wir im Nullmodell (leeren Modell) noch keine Prädiktoren aufnehmen. Wichtig ist jedoch, dass der Haken unten links bei „Konstanten Term einschließen“ gesetzt ist, da wir einen sog. Fixed Intercept schätzen, also ein durchschnittlichen Achsenabschnitt über alle Klassen hinweg.
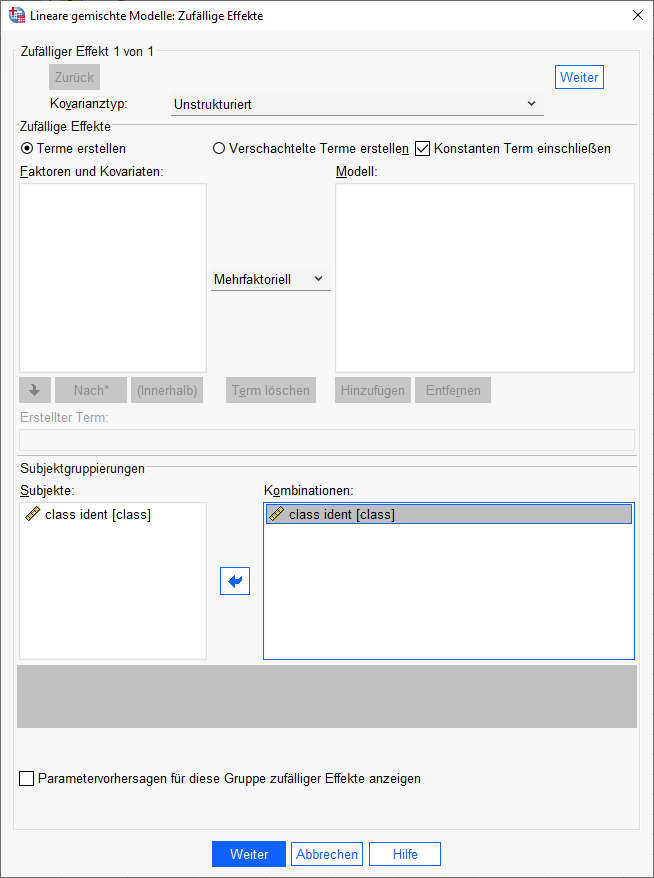
Bei den zufälligen Effekten (Menüpunkt: Zufällig...) müssen wir mehrere Eingaben vornehmen. Zum ersten würde ich den Kovarianztyp bereits hier auf „Unstrukturiert“ umstellen, auch wenn das erst später in Modellen mit Random Slopes inhaltlich erforderlich ist – aber wenn man es dann später vergisst, bekommt man falsche Ergebnisse. Zum zweiten setzen wir den Haken rechts oben bei „Konstanten Term einschließen“, damit wir eine Schätzung für den Random Intercept bekommen. Und bei Subjektgruppierungen ziehen wir die Gruppierungsvariable (hier: class) in das Feld „Kombinationen“.
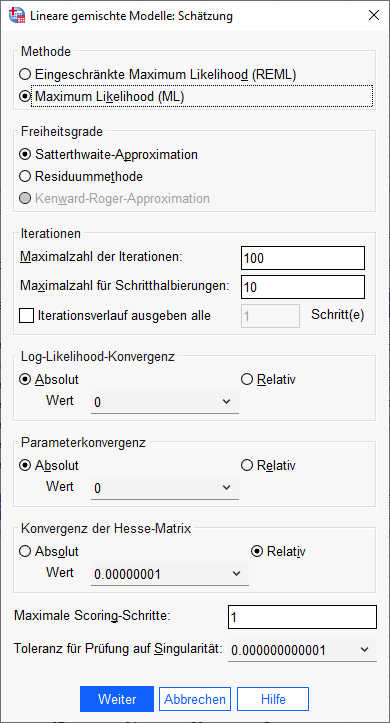
Bei der Schätzung habe ich in diesem Fall die Methode auf „Maximum Likelihood (ML)“, weil auch Hox (2010) im Buch mit ML statt mit REML (restricted maximum likelihood) gearbeitet haben, so dass man die Ergebnisse mit den Ergebnissen aus Kapitel 2 des o.g. Buchs vergleichen kann. Welches der beiden Verfahren, ML oder REML, besser ist, hängt von der Fragestellung ab; siehe dazu auch Hox (2010).
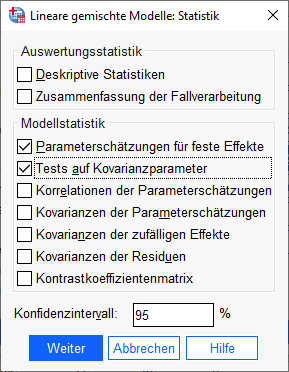
Als Statistiken fordere ich mindestens die „Parameterschätzungen für feste Effekte“ und die „Tests auf Kovarianzparameter“ an.
Jetzt kann man das Modell schätzten und erhält eine Reihe von Auswertungen.
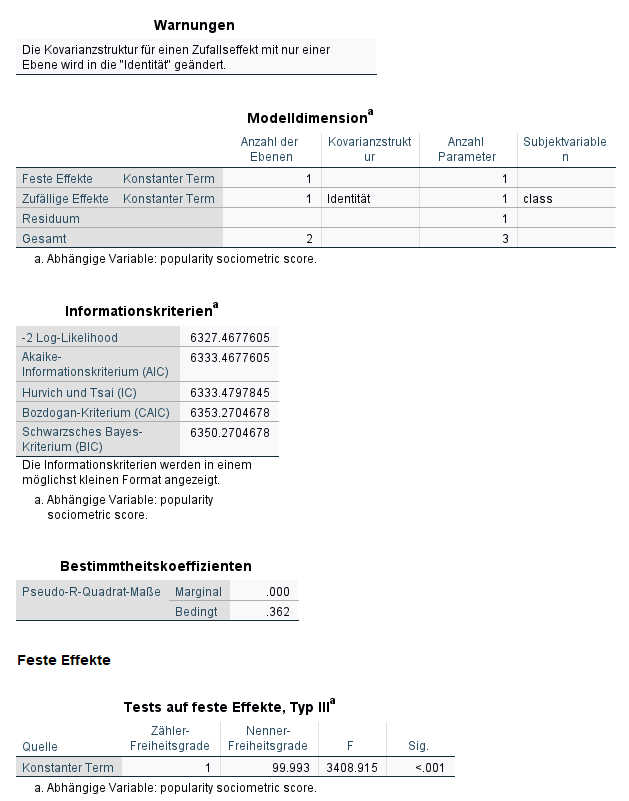
Zunächst sehe wir eine Warnung wegen der Varianzstruktur – die ist hier unproblematisch. Dann sehen wir, welche Modellparameter geschätzt wurden. Hier sind das eine fester Effekt (hier Fixed Intercept), und zwei Zufallseffekte (hier Random Intercept sowie das Level 1 Residuum).
Inhaltlich interessant ist die Tabelle mit den Informationskriterien. Das erste, - 2 Log-Likelihood, wird bei Mehrebenenmodellen häufig auch Deviance genannt und ist ein Maß für die Modellgüte. Dabei gilt, dass ein kleinerer Wert einem besseren Modellfit entspricht. Wir werden im Zuge des Tutorials sehen, wie dieser Wert mit der Aufnahme zusätzlicher Parameter besser (= kleiner) wird.

Unter der Schätzung fester Parameter finden wir hier bisher nur einen Parameter, den konstanten Term (= Intercept). Da wir keine Prädiktoren in unserem Nullmodell haben, ist die zugleich eine Schätzung für die mittleren Werte der Kriteriumsvariable (Popularität).
Unter Kovarianzparameter finden wir zwei Schätzungen. Zum einen die Schätzung für das Level 1 Residuum, hier 1.222. Diese Schätzung zeigt, wie stark die Popularitätswerte der einzelnen Schülerinnen und Schüler im Mittel von der durchschnittlichen Popularität ihrer Schulklasse abweichen. Für ein intuitiv verständlicheres Maß kann es dabei sinnvoll sein, die Quadratwurzel dieser Schätzungen zu nehmen, so dass man dann nicht mehr die Varianz, sondern die Standardabweichung erhält, die in der gleichen Metrik ausgewiesen wird wie die festen Parameter .
Und zum anderen die Schätzung für die Schwankung des Intercepts als Random Intercept auf Level 2, hier 0.695. Diese Schätzung zeigt, wie stark sich die Intercepts der verschiedenen Schulklassen vom Gesamtintercept unterscheiden (und hier im Nullmodell: wie stark sich die Mittelwerte der Schulklassen vom Gesamtmittelwert unterscheiden).
Aus diesen beiden Schätzungen der Zufallseffekte kann man jetzt die Intraklassenkorrelation ICC berechnen. Dabei teilt man die Level 2 Varianz (random intercept) durch die Summe von Level 2 und Level 1 Varianz:
0.695 / (0.695 + 1.222) = .363.
3. Modell mit Fixed Slopes / Random Intercept
Unser nächstes Modell ist das erste echte Modell, ein Modell mit Fixed Effects. Jetzt werden die beiden Level 1 Prädiktoren Extraversion und Geschlecht und der Level 2 Prädiktor Berufserfahrung der Lehrkraft zusätzlich als Fixed Effects in das Modell eingeschlossen. Das bedeutet, dass die Effekte für diese drei Variablen in allen Schulklassen gleich geschätzt werden (anders als später bei Random Slopes, wo unterschiedliche Schätzungen je nach Schulklasse möglich werden).
Das Bild „Subjekte und Wiederholungen angeben“ bleibt gleich, die ersten Ergänzungen nehmen wir vor im Dialog „Lineare gemischte Modelle“.
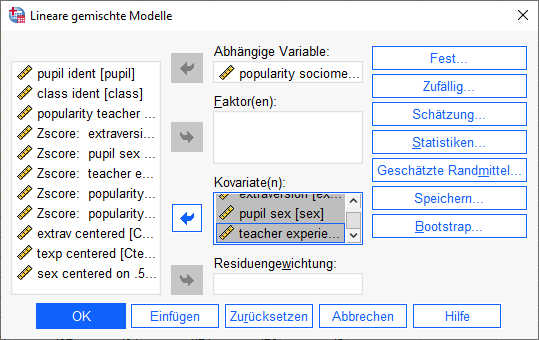
Hier sind jetzt zusätzlich die drei Prädiktoren (extraversion, sex, teacher experience) in das Feld „Kovariaten“ aufgenommen.
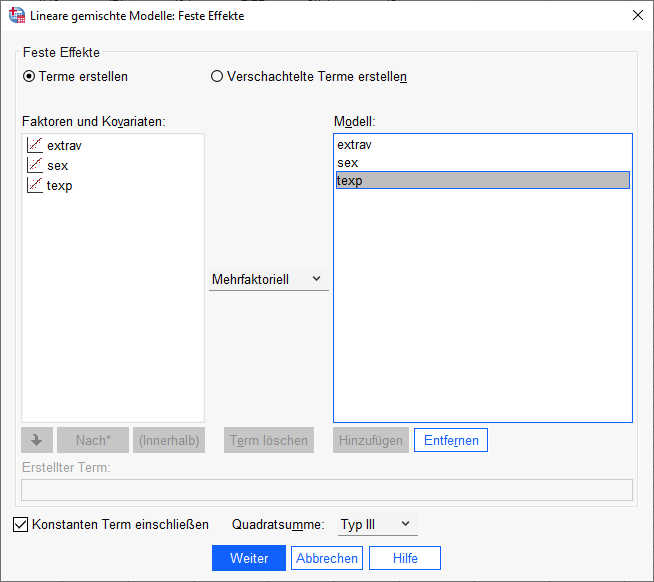
Bei den festen Effekten fügen wir mit der Schaltfläche „Hinzufügen“ die drei Prädiktoren einzeln rechts in das Feld für das Modell ein. Wenn Sie stattdessen die drei Variablen zusammen markieren und einfügen, dann bekommen Sie zusätzlich noch alle möglichen Interaktionsterme, die Sie jetzt noch nicht gebrauchen können (zu sog. Cross Level Interactions kommen wir später noch).
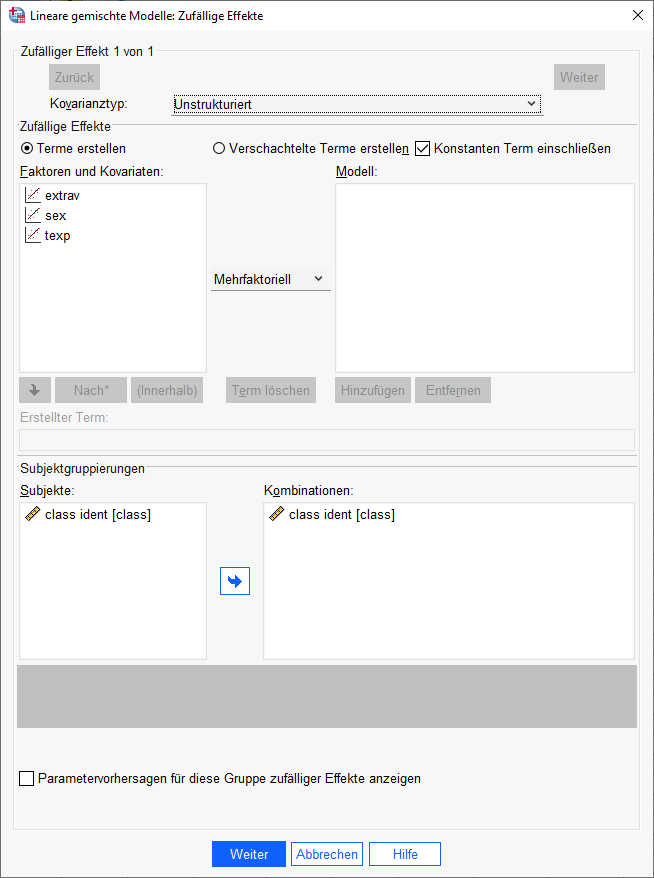
Bei den Zufallseffekten ändert sich noch nichts – Zufallseffekte für die Prädiktoren (= Random Slopes) wollen wir erst in einem späteren Schritt einschließen.
Die anderen Dialogboxen bleiben gleich, so dass wir jetzt dieses Modell schätzen können.
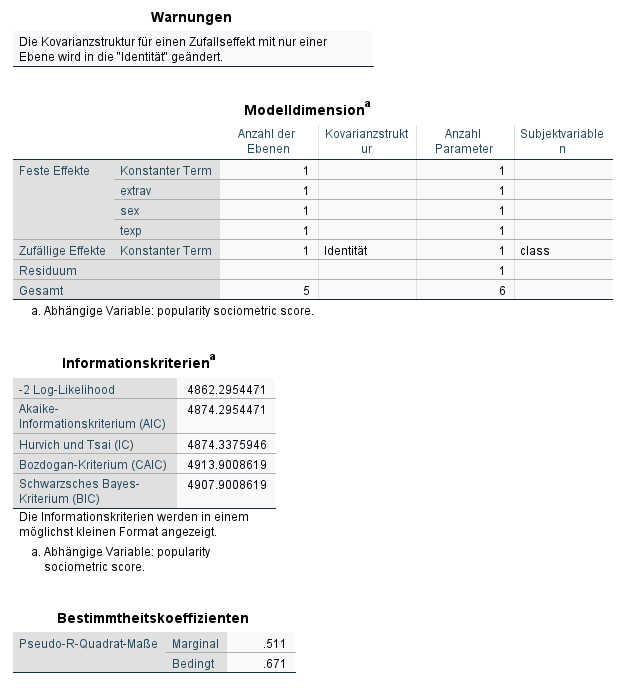
Wir sehen jetzt, dass die Deviance sich auf 4862.3 verbessert hat durch die Aufnahme der Prädiktoren.
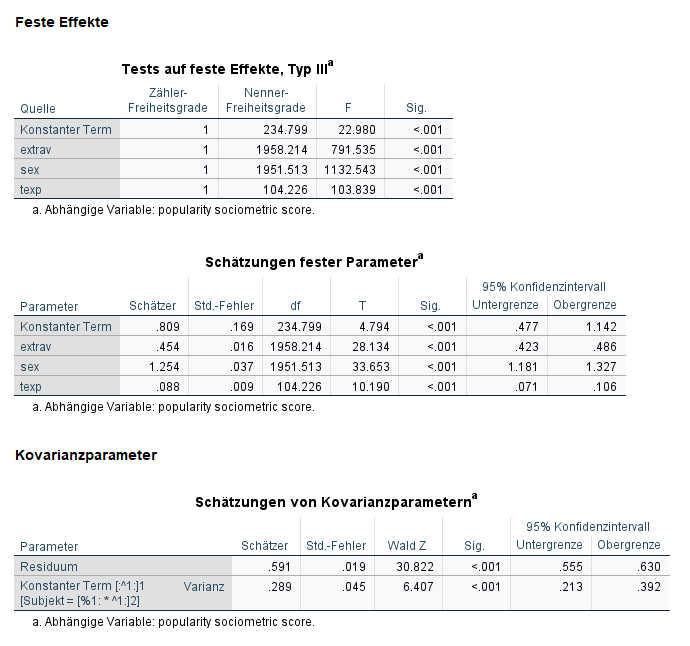
Bei der Schätzung der festen Parameter sehen wir in der Spalte „Schätzer“ die Effekte für die Prädiktoren. Alle drei haben einen signifikanten Einfluss auf die Popularität der Schülerinnen und Schüler.
Wenn wir die Kovarianzparameter mit den gleichen Werten des Nullmodells vergleichen, sehen wir, dass die Zufallseffekte kleiner geworden sind. Das liegt daran, dass unsere drei neu aufgenommen Prädiktoren einiges an zusätzlicher Varianz erklären, so dass der unerklärte Teil geringer ist, der sich in den Zufallseffekten widerspiegelt.
4. Modell mit Random Slopes
Jetzt wollen wir unser Modell um random slopes ergänzen. wir lassen es dann also zu, dass die Level 1 Prädiktoren in verschiedenen Schulklassen unterschiedliche Effekte (hinsichtlich Stärke, im Extremfall sogar hinsichtlich Vorzeichen) haben können. Das macht aber nur für Level 1 Prädiktoren Sinn, für einen Level 2 Prädiktor (hier: Berufserfahrung) ist eine Random Slope nicht möglich, da dieser Prädiktor für alle Personen in einer Schulklasse gleich ist und man insofern kein gesonderten Slopes je Klasse schätzen kann.
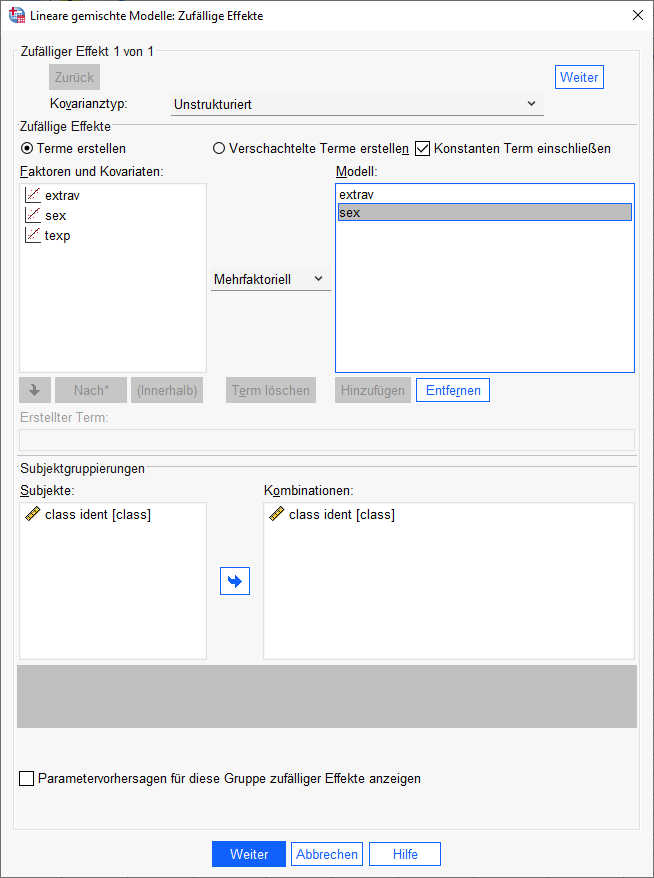
Um Random Slopes schätzen zu können, nehmen wir gegenüber dem vorherigen Modell eine Änderung im Dialog „Zufällige Effekte“ vor. Hier fügen wir die beiden Variablen extrav und sex (einzeln) rechts in das Feld „Modell“ ein.
Und spätestens jetzt ist es notwendig, dass als Kovarianztyp der Typ „Unstrukturiert“ eingestellt ist, soweit Sie diese Einstellung nicht bereits in einem früheren Schritt vorgenommen haben.

Hier erhalten wir die Warnung, dass die Modellschätzung nicht konvergiert ist. Das Programm konnte also keine stabile Schätzung für dieses Modell berechnen und die Ergebnisse können wir nicht inhaltlich interpretieren.
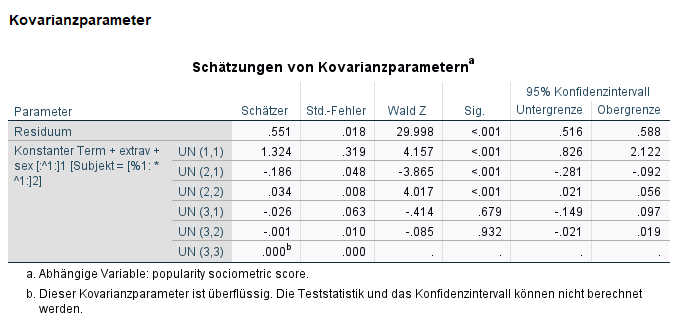
Bei der Schätzung der Kovarianzparameter erhalten wir den Hinweis: „Dieser Kovarianzparameter ist überflüssig“ für den Parameter UN(3,3). Wenn beide Ziffern in der Klammer gleich sind, handelt es sich um eine Varianzschätzung (bei zwei ungleichen Ziffern wäre es eine Kovarianzschätzung). Hier gibt es drei Zufallsparameter: Konstante, Extraversion, Geschlecht. Hier ist das Problem bei dem dritten Zufallsparameter aufgetreten, also dem Geschlecht, das anscheinend keine Varianz aufweist (dessen Effekt also nicht zwischen den Schulklassen schwankt).
Daher werden wir jetzt die Modellschätzung wiederholen, jedoch jetzt nur noch mit einer Random Slope für Extraversion und nicht mehr für Geschlecht.
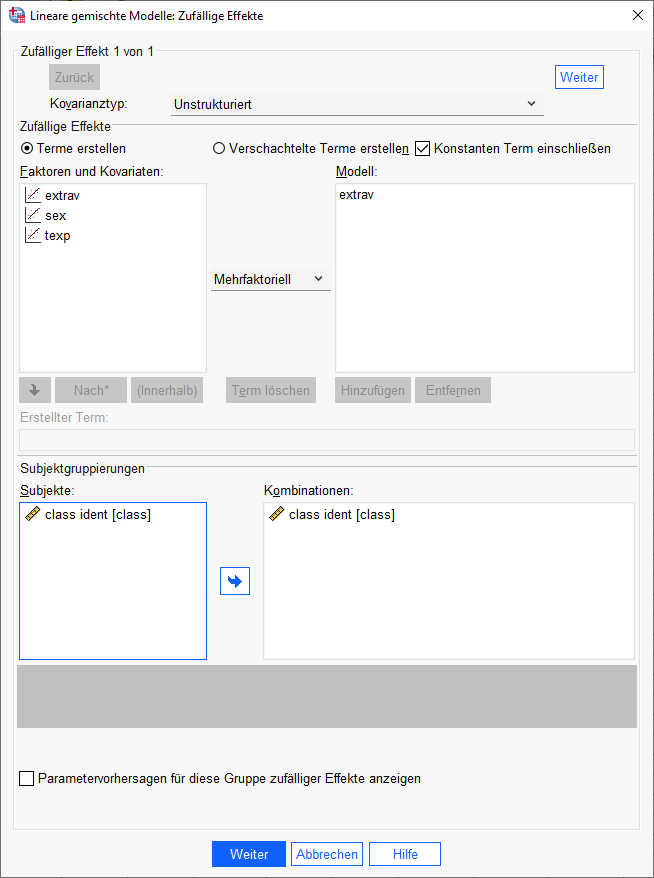
Jetzt ist nur noch Extraversion rechts unter Modell aufgeführt, nachdem die Variable sex wieder nach links in die Liste „Faktoren und Kovariaten“ verlagert worden ist.

Wieder erscheint die Warnung, dass keine Konvergenz erreicht wurde.
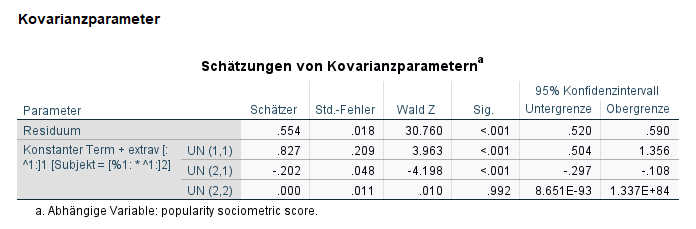
Allerdings erscheint jetzt bei der Schätzung der Kovarianzparameter nicht mehr ein Hinweis, dass einer der Parameter überflüssig sei.
Daher könnte das Problem einfach sein, dass dieses Modell relativ lange braucht, um stabil geschätzt zu werden.
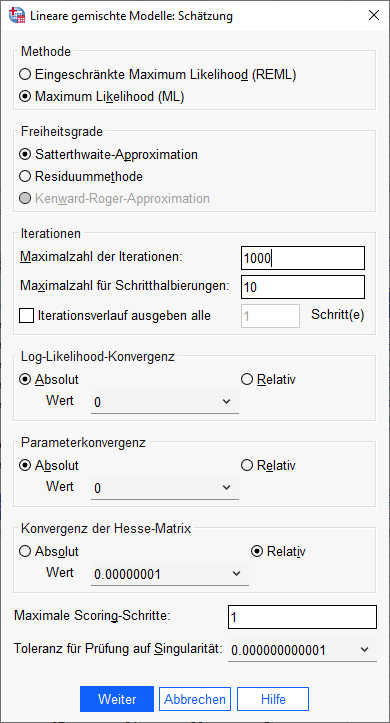
Daher erhöhen wir im Dialog „Schätzung“ die Maximalzahl der Iterationen auf 1000 und wiederholen die Schätzung.
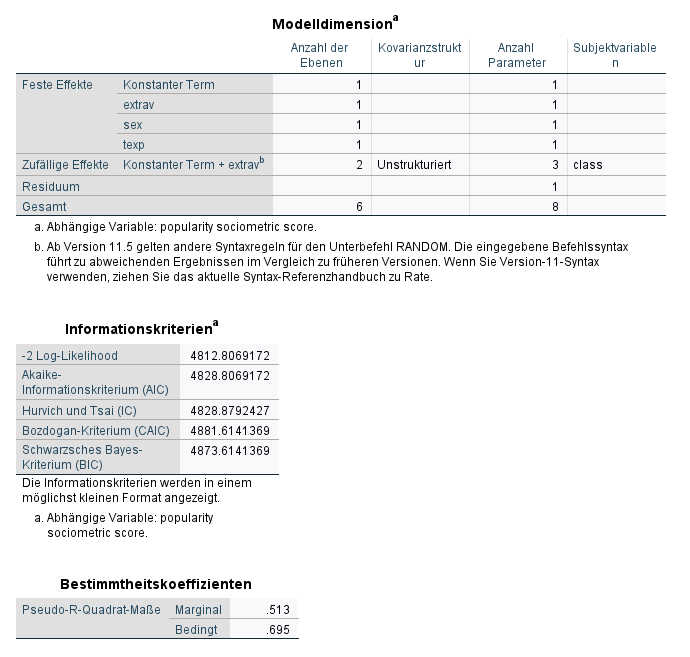
Jetzt ist die Warnung hinsichtlich mangelnder Konvergenz verschwunden, die erhöhte Anzahl der Iterationen hat also dieses Problem offenbar gelöst.
Bei den Modelldimensionen sehen wir, dass neben 4 Fixed Effects (Intercept und die drei Prädiktoren) und dem Level 1 Residuum noch 3 zufällige Effekte geschätzt wurden. Dies sind das Random Intercept, die Random Slope für die Variable Extraversion sowie die Kovarianz zwischen diesen beiden Zufallsparametern.
Die Deviance (= - 2 log likelihood) weist jetzt einen Wert von 4812.8 auf, das Modell ist also gegenüber dem Modell nur mit Fixed Slopes noch einmal verbessert.
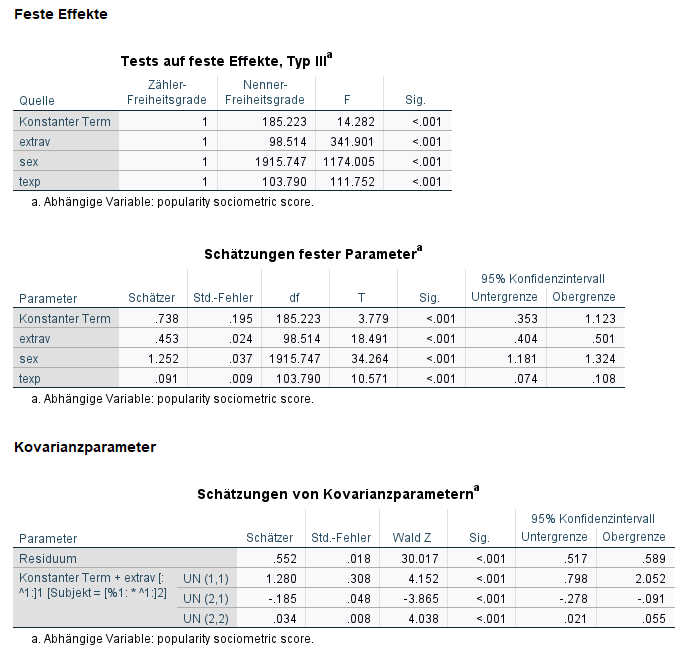
Die Interpretation der festen Effekte hat sich nicht geändert.
Bei den Kovarianzparametern ist jetzt der Effekt (1, 1) das Random Intercept, der Effekt (2, 2) die Random Slope für die Extraversion und (2, 1) die Kovarianz zwischen diesen beiden Zufallseffekten. Alle drei sind signifikant; aus der signifikanten Random Slope für Extraversion folgt, dass sich der Effekt von Extraversion auf die Popularität in den verschiedenen Klassen unterscheidet.
5. Modell mit Cross-Level Interaktion
Im vorherigen Modell hatten wir gesehen, dass es eine signifikante Varianz in Effekt der Extraversion auf die Popularität gab. Die Frage ist, warum das der Fall ist. Ein möglicher Grund könnte sein, dass sich dieser Effekt in Abhängigkeit von der Berufserfahrung der Lehrkraft unterscheidet – dass also in Klassen mit erfahreneren Lehrkräften der Effekt der Extraversion anders (größer oder kleiner) ist als in Klassen mit unerfahreneren Lehrkräften.
Um das zu prüfen, schätzen wir jetzt ein Modell mit Cross Level Interaction, also mit einer Interaktion zwischen einer Level 1 Variable (Extraversion) und einer Level 2 Variable (Berufserfahrung der Lehrkraft).
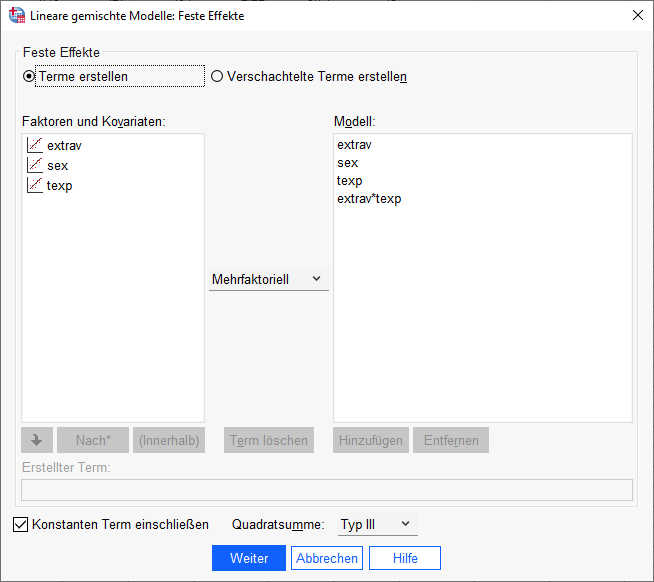
Dazu gehen wir in den Dialog „Feste Effekte“, markieren extrav und texp und klicken dann auf „Hinzufügen“. Damit ist zusätzlich auf der rechten Seite unter „Modell“ auch der Interaktionsterm dieser beiden Variablen enthalten. Dieses Modell schätzen wir anschließend.

Die Deviance hat sich nochmals verbessert, auf 4747.6.
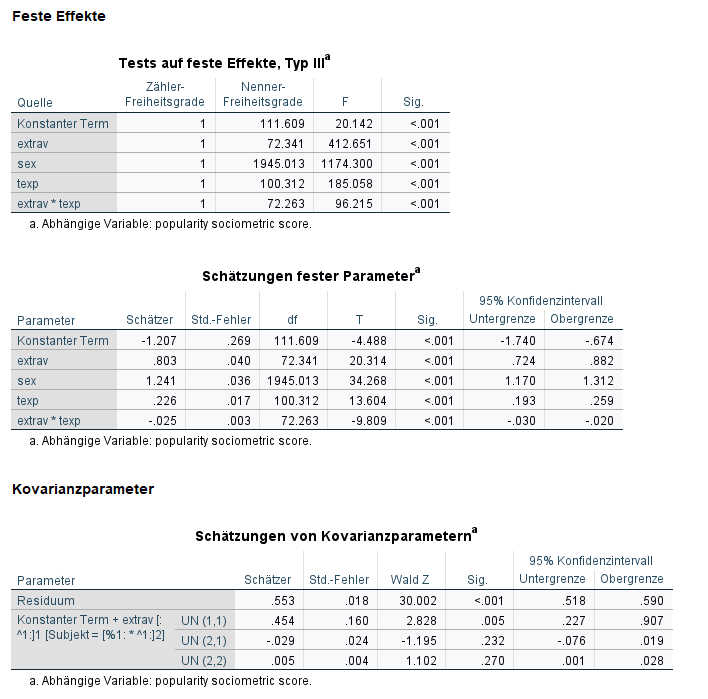
Bei den festen Parameterschätzungen ist jetzt die Cross-Level Interaktion hinzugekommen, etrav * texp. Die signifikante negative Cross-Level Interaktion besagt, dass der Effekt von Extraversion auf Popularität niedriger ist in Klassen mit erfahreneren Lehrkräften. Wir könnten jetzt noch ein Modell ohne Random Slope für Extraversion schätzen und gucken, ob sich die Deviance nicht wesentlich verschlechtert, da unter den Kovarianzparametern die Random Slope für Extraversion nicht mehr signifikant ist (was darauf hindeutet, dass tatsächlich die Berufserfahrung der Lehrkräfte die Erklärung für die bisherige Schwankung in der Slope für Extraversion war), worauf ich in diesem Tutorial allerdings verzichte.
Bei einer signifikanten Interaktion ist es üblich, sogenannte Simple Slopes zu berechnen, also bedingte Effekte für verschiedene Ausprägungen des Moderators. Hier finden Sie einen entsprechenden Online-Rechner: http://www.quantpsy.org/interact/hlm2.htm
6. Daten für Voraussetzungsprüfung
Auch Mehrebenenmodelle haben Voraussetzungen, die man prüfen muss, bevor man die Ergebnisse interpretiert. Im wesentlichen gleichen die Voraussetzungen der linearen Regression, wobei die verletzte Voraussetzung der Unabhängigkeit der Residuen der Anlass war, eine Mehrebenenanalyse durchzuführen.
Die Details der Voraussetzungsprüfung sprengen den Rahmen dieses Tutorials. Was hier jedoch erläutert werden soll ist, wo Sie die nötigen Daten für die Voraussetzungsprüfung bekommen.
Die meisten Voraussetzungen bei der Regression betreffen die Residuen, also die Zufallseffekte. Allerdings haben wir im Bereich der Mehrebenenanalyse Zufallseffekte auf verschiedenen Ebenen der Analyse, und die Voraussetzungen gelten für alle diese Zufallseffekte. In unserem o.g. Modell müssen wir also die Voraussetzungen gesondert prüfen sowohl für die Level 1 Residuen als auch für die Zufallseffekte auf Level 2 (Random Intercept, Random Slope).
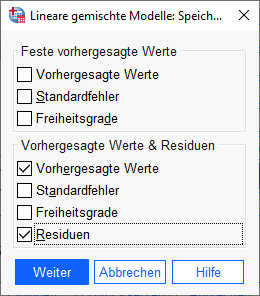
Vorhergesagte Werte und Residuen auf Level 1 können wir anfordern im Dialog „Speichern“. Diese werden dann in der Datentabelle gespeichert.
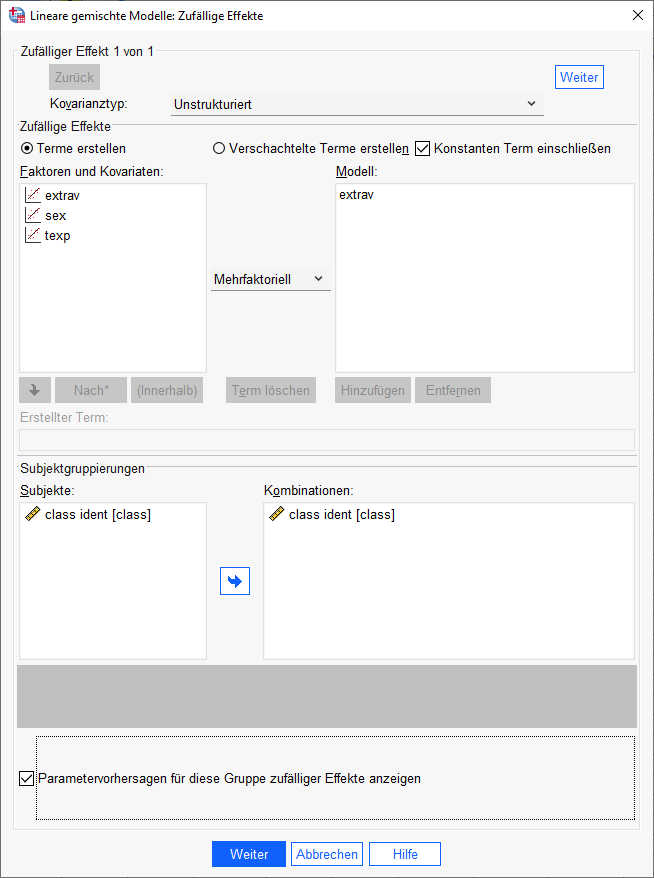
Die geschätzten Werte für die Zufallseffekte auf Level 2 fordern wir an im Dialog „Zufällige Effekte“, indem wir unten den Haken setzen bei „Parametervorhersage für diese Gruppe zufälliger Effekte anzeigen“.
Die Tabelle mit den geschätzten Level 2 Zufallseffekten ist Teil des Outputs. Wir können sie aus dem Output exportieren in eine neue Datentabelle und dann entsprechend auswerten (wobei die Aufbereitung der exportierten Daten relativ umständlich ist).
7. Literatur
Hox, J. J. (2010). Multilevel analysis: Techniques and applications (2nd edition). Routledge.